This article explains the concept of thread synchronization in the case of multithreading in the Python programming language.
Thread Synchronization
Thread synchronization is defined as a mechanism that prevents two or more concurrent threads from executing specific segments of a program simultaneously, known as critical sections.
A critical section refers to a part of a program that accesses shared resources.
For example, in the diagram below, three threads are trying to access shared resources or critical sections simultaneously.
Concurrent access to shared resources can lead to race conditions.
A race condition occurs when two or more threads can access shared data and attempt to modify it at the same time. As a result, the variable values become unpredictable and can vary depending on the timing of context switches in the process.
To understand the concept of race conditions, consider the program below.
| import threading# global variable xx = 0def increment(): “”” function to increment global variable x “”” global x x += 1def thread_task(): “”” task for thread calls increment function 100000 times. “”” for _ in range(100000): increment()def main_task(): global x # setting global variable x as 0 x = 0 # creating threads t1 = threading.Thread(target=thread_task) t2 = threading.Thread(target=thread_task) # start threads t1.start() t2.start() # wait until threads finish their job t1.join() t2.join()if __name__ == “__main__”: for i in range(10): main_task() print(“Iteration {0}: x = {1}”.format(i,x)) |
Output:
Iteration 0: x = 175005
Iteration 1: x = 200000
Iteration 2: x = 200000
Iteration 3: x = 169432
Iteration 4: x = 153316
Iteration 5: x = 200000
Iteration 6: x = 167322
Iteration 7: x = 200000
Iteration 8: x = 169917
Iteration 9: x = 153589In the above program:
- The main_task function creates two threads t1 and t2 and sets the global variable x to 0.
- Each thread has a target function thread_task that calls the increment function 100000 times.
- The increment function increases the global variable x by 1 each time it is called.
The expected final value of x is 200000, but the value obtained by repeating the main_task function 10 times varies.
This occurs due to concurrent access to the shared variable x. This unpredictability of the x value is simply a race condition.
Below is a diagram showing how a race condition occurs in the above program.
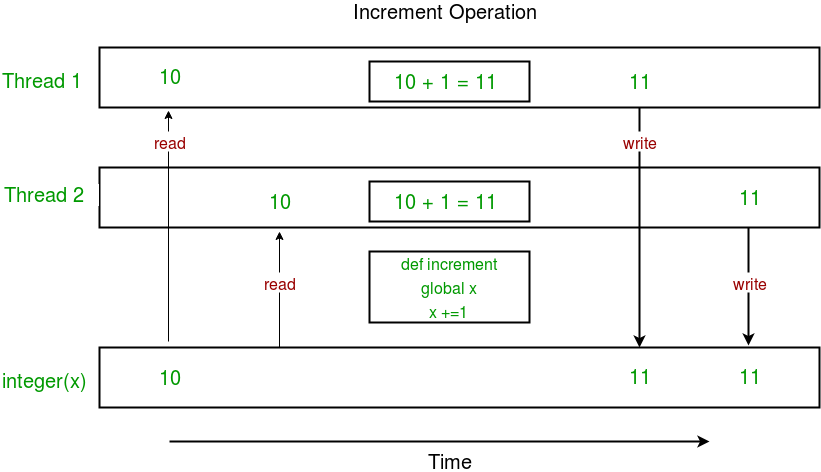
In the above diagram, the expected value of x is 12, but due to the race condition, it turned out to be 11!
Therefore, there is a need for tools to properly synchronize multiple threads.
Using Locks
The threading module provides the Lock class to handle race conditions. Locks are implemented using Semaphore objects provided by the operating system.
A semaphore is a synchronization object that controls access to common resources by multiple processes/threads in a parallel programming environment. It is simply a value located in a designated area of the operating system (or kernel) storage that each process/thread can check and modify. Depending on the discovered value, the process/thread can either use the resource or confirm that the resource is already in use and must wait for a certain period before retrying. A semaphore can be binary (0 or 1) or can have additional values. Generally, a process/thread that uses a semaphore checks the value and then modifies it to reflect that a subsequent semaphore user must wait.
The Lock class provides the following methods:
- acquire([blocking]) : Acquires the lock. The lock can be blocking or non-blocking.
- Calling with the blocking argument set to True (default) causes the thread execution to block until the lock is released, after which the lock is set and True is returned.
- Calling with the blocking argument set to False causes the thread execution not to block. If the lock is released, it sets the lock and returns True; otherwise, it immediately returns False.
- release() : Releases the lock.
- If the lock is locked, it resets to the unlocked state and returns. If there are other threads waiting for the lock to be released, exactly one of them is allowed to proceed.
- If the lock is already released, a ThreadError is raised.
Consider the following example.
| import threading# global variable xx = 0def increment(): “”” function to increment global variable x “”” global x x += 1def thread_task(lock): “”” task for thread calls increment function 100000 times. “”” for _ in range(100000): lock.acquire() increment() lock.release()def main_task(): global x # setting global variable x as 0 x = 0 # creating a lock lock = threading.Lock() # creating threads t1 = threading.Thread(target=thread_task, args=(lock,)) t2 = threading.Thread(target=thread_task, args=(lock,)) # start threads t1.start() t2.start() # wait until threads finish their job t1.join() t2.join()if __name__ == “__main__”: for i in range(10): main_task() print(“Iteration {0}: x = {1}”.format(i,x)) |
Output:
Iteration 0: x = 200000
Iteration 1: x = 200000
Iteration 2: x = 200000
Iteration 3: x = 200000
Iteration 4: x = 200000
Iteration 5: x = 200000
Iteration 6: x = 200000
Iteration 7: x = 200000
Iteration 8: x = 200000
Iteration 9: x = 200000Now, let’s understand the code step by step.
- First, a Lock object is created using
lock = threading.Lock() - Then, the lock is passed as an argument to the target function.
t1 = threading.Thread(target=thread_task, args=(lock,)) t2 = threading.Thread(target=thread_task, args=(lock,)) - In the critical section of the target function, the lock.acquire() method is used to apply the lock. Once the lock is acquired, the lock.release() method is used to release the lock, preventing other threads from accessing the critical section (in this case, the increment function) until it is released.
lock.acquire() increment() lock.release()As seen in the results, the final value of x results in 200000 each time (the final expected result).
Below is a diagram illustrating the lock implementation in the above program.
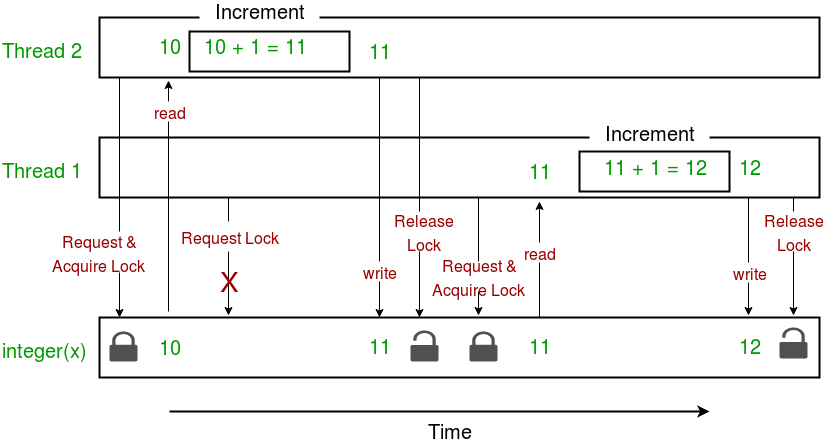
This concludes the tutorial series on multithreading in Python.
In conclusion, here are some advantages and disadvantages of multithreading:
Advantages:
- Does not block the user. Threads are independent of each other.
- Threads run tasks in parallel, making more efficient use of system resources.
- Improved performance on multiprocessor systems.
- Multithreaded servers and interactive GUIs exclusively use multithreading.
Disadvantages:
- As the number of threads increases, complexity also increases.
- Synchronization of shared resources (objects, data) is necessary.
- Debugging can be difficult, and results may be unpredictable.
- Potential deadlocks leading to starvation, meaning some threads may not get resources due to poor design.
- Thread configuration and synchronization can be CPU/memory intensive.