이 기사에서는 Python 프로그래밍 언어에서 멀티스레딩 의 경우 스레드 동기화 개념에 대해 설명합니다 .
스레드 간 동기화
스레드 동기화는 두 개 이상의 동시 스레드가 임계 섹션 으로 알려진 일부 특정 프로그램 세그먼트를 동시에 실행하지 않도록 하는 메커니즘으로 정의됩니다 .
중요 섹션은 공유 리소스에 액세스하는 프로그램 부분을 나타냅니다.
예를 들어 아래 다이어그램에서는 3개의 스레드가 동시에 공유 리소스 또는 중요 섹션에 액세스하려고 합니다.
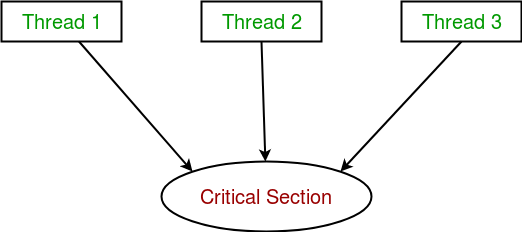
공유 리소스에 대한 동시 액세스는 경쟁 조건 을 초래할 수 있습니다 .
경쟁 조건은 두 개 이상의 스레드가 공유 데이터에 액세스할 수 있고 동시에 변경하려고 할 때 발생합니다. 결과적으로 변수 값은 예측할 수 없으며 프로세스의 컨텍스트 전환 타이밍에 따라 달라질 수 있습니다.
경쟁 조건의 개념을 이해하려면 아래 프로그램을 고려하십시오.
| import threading# global variable xx = 0def increment(): “”” function to increment global variable x “”” global x x += 1def thread_task(): “”” task for thread calls increment function 100000 times. “”” for _ in range(100000): increment()def main_task(): global x # setting global variable x as 0 x = 0 # creating threads t1 = threading.Thread(target=thread_task) t2 = threading.Thread(target=thread_task) # start threads t1.start() t2.start() # wait until threads finish their job t1.join() t2.join()if __name__ == “__main__”: for i in range(10): main_task() print(“Iteration {0}: x = {1}”.format(i,x)) |
산출:
Iteration 0: x = 175005
Iteration 1: x = 200000
Iteration 2: x = 200000
Iteration 3: x = 169432
Iteration 4: x = 153316
Iteration 5: x = 200000
Iteration 6: x = 167322
Iteration 7: x = 200000
Iteration 8: x = 169917
Iteration 9: x = 153589위 프로그램에서:
- main_task 함수 에 두 개의 스레드 t1 과 t2가 생성되고 전역 변수 x 가 0으로 설정됩니다.
- 각 스레드에는 증분 함수가 100000번 호출되는 대상 함수 thread_task 가 있습니다.
- increment 함수는 호출할 때마다 전역 변수 x를 1씩 증가시킵니다.
x 의 예상 최종 값 은 200000이지만 main_task 함수 를 10번 반복하여 얻는 값은 일부 다릅니다.
이는 공유 변수 x 에 대한 스레드의 동시 액세스로 인해 발생합니다 . x 값의 이러한 예측 불가능성은 경쟁 조건 에 지나지 않습니다 .
아래에는 위 프로그램에서 경쟁 조건이 어떻게 발생하는지 보여주는 다이어그램이 나와 있습니다 .
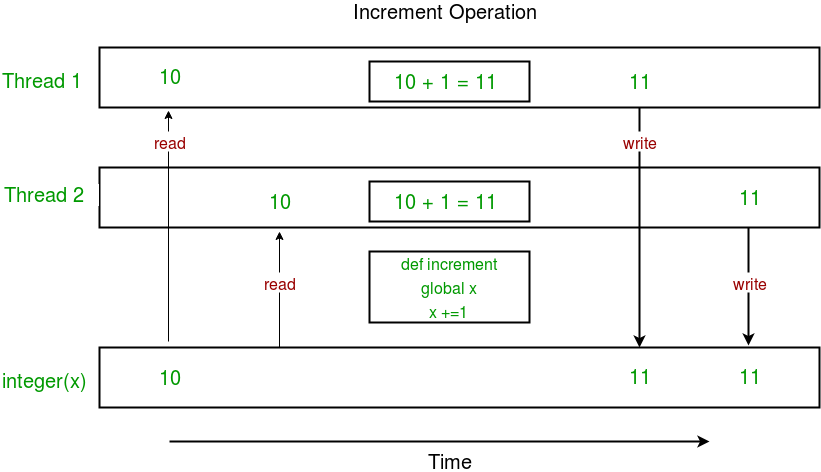
위 다이어그램에서 x 의 예상 값은 12이지만 경쟁 조건으로 인해 11로 밝혀졌습니다!
따라서 여러 스레드 간의 적절한 동기화를 위한 도구가 필요합니다.
잠금 사용
스레딩 모듈은 경쟁 조건을 처리하기 위해 Lock 클래스를 제공합니다. 잠금은 운영 체제에서 제공하는 Semaphore 개체를 사용하여 구현됩니다 .
세마포어는 병렬 프로그래밍 환경에서 공통 리소스에 대한 여러 프로세스/스레드의 액세스를 제어하는 동기화 개체입니다. 이는 단순히 각 프로세스/스레드가 확인하고 변경할 수 있는 운영 체제(또는 커널) 저장소의 지정된 위치에 있는 값입니다. 발견된 값에 따라 프로세스/스레드는 리소스를 사용할 수 있거나 리소스가 이미 사용 중임을 확인하고 다시 시도하기 전에 일정 기간 동안 기다려야 합니다. 세마포어는 이진수(0 또는 1)이거나 추가 값을 가질 수 있습니다. 일반적으로 세마포어를 사용하는 프로세스/스레드는 값을 확인한 다음 리소스를 사용하는 경우 후속 세마포어 사용자가 기다려야 함을 알 수 있도록 이를 반영하도록 값을 변경합니다.
Lock 클래스는 다음과 같은 메소드를 제공합니다:
- acquire([blocking]) : 잠금을 획득합니다. 잠금은 차단 또는 비차단일 수 있습니다.
- 차단 인수를 True (기본값)로 설정하여 호출하면 잠금이 해제될 때까지 스레드 실행이 차단된 다음 잠금이 잠김으로 설정되고 True 를 반환합니다 .
- 차단 인수를 False 로 설정하여 호출하면 스레드 실행이 차단되지 않습니다. 잠금이 해제된 경우 잠금으로 설정하고 True를 반환하고, 그렇지 않으면 즉시 False를 반환합니다 .
- release() : 잠금을 해제합니다.
- 자물쇠가 잠기면 잠금 해제 상태로 재설정하고 돌아오세요. 잠금이 해제될 때까지 대기하는 다른 스레드가 차단된 경우 그 중 정확히 하나만 진행하도록 허용합니다.
- 잠금이 이미 잠금 해제된 경우 ThreadError 가 발생합니다.
아래 주어진 예를 고려하십시오.
| import threading# global variable xx = 0def increment(): “”” function to increment global variable x “”” global x x += 1def thread_task(lock): “”” task for thread calls increment function 100000 times. “”” for _ in range(100000): lock.acquire() increment() lock.release()def main_task(): global x # setting global variable x as 0 x = 0 # creating a lock lock = threading.Lock() # creating threads t1 = threading.Thread(target=thread_task, args=(lock,)) t2 = threading.Thread(target=thread_task, args=(lock,)) # start threads t1.start() t2.start() # wait until threads finish their job t1.join() t2.join()if __name__ == “__main__”: for i in range(10): main_task() print(“Iteration {0}: x = {1}”.format(i,x)) |
산출:
Iteration 0: x = 200000
Iteration 1: x = 200000
Iteration 2: x = 200000
Iteration 3: x = 200000
Iteration 4: x = 200000
Iteration 5: x = 200000
Iteration 6: x = 200000
Iteration 7: x = 200000
Iteration 8: x = 200000
Iteration 9: x = 200000위의 코드를 단계별로 이해해 보겠습니다.
- 먼저 다음을 사용하여 Lock 객체를 생성합니다.
lock = threading.Lock() - 그런 다음 잠금이 대상 함수 인수로 전달됩니다.
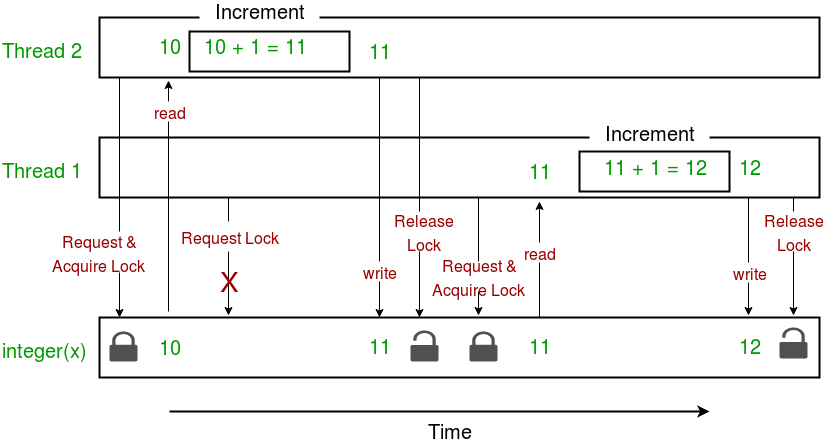
t1 = threading.Thread(target=thread_task, args=(lock,)) t2 = threading.Thread(target=thread_task, args=(lock,)) - 대상 함수의 중요한 섹션에서는 lock.acquire() 메서드를 사용하여 잠금을 적용합니다. 잠금이 획득되면 lock.release() 메서드를 사용하여 잠금이 해제될 때까지 다른 스레드는 임계 섹션(여기서는 증분 함수) 에 액세스할 수 없습니다 .
lock.acquire() increment() lock.release()결과에서 볼 수 있듯이 x 의 최종 값은 매번 200000으로 나옵니다(최종 예상 결과).
다음은 위 프로그램에서 잠금 구현을 설명하는 다이어그램입니다.
이로써 Python의 멀티스레딩 에 대한 튜토리얼 시리즈가 끝났습니다 .
마지막으로 멀티스레딩의 몇 가지 장점과 단점은 다음과 같습니다.
장점:
- 사용자를 차단하지 않습니다. 스레드는 서로 독립적이기 때문입니다.
- 스레드가 작업을 병렬로 실행하므로 시스템 리소스를 더 효율적으로 사용할 수 있습니다.
- 다중 프로세서 시스템의 성능이 향상되었습니다.
- 다중 스레드 서버 및 대화형 GUI는 다중 스레드를 독점적으로 사용합니다.
단점:
- 스레드 수가 증가하면 복잡성도 증가합니다.
- 공유 리소스(객체, 데이터)의 동기화가 필요합니다.
- 디버깅이 어렵고 결과를 예측할 수 없는 경우도 있습니다.
- 기아 상태로 이어지는 잠재적인 교착 상태. 즉 일부 스레드가 잘못된 디자인으로 제공되지 않을 수 있습니다.
- 스레드 구성 및 동기화는 CPU/메모리를 많이 사용합니다.